seata-分布式事务管理器
前面讲了tx-lcn实现的分布式事务,其原理是不释放连接,暂停提交。
1. tx-lcn相关的原理(引入阿里seata)
lcn模式是两阶段提交的一种实现,2pc提交传统方案是在数据库层面实现的,tx-lcn在数据库层面之上做了实现。
传统的方案图如下.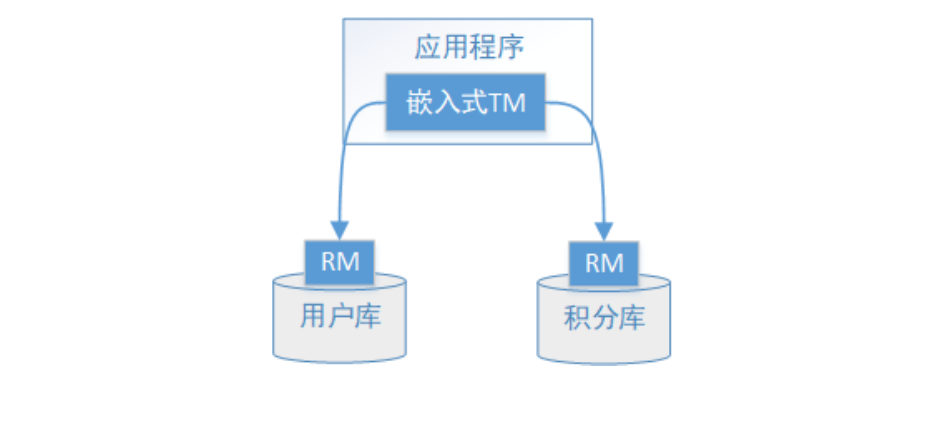
1、应用程序(AP)持有用户库和积分库两个数据源。
2、应用程序(AP)通过TM通知用户库RM新增用户,同时通知积分库RM为该用户新增积分,RM此时并未提交事
务,此时用户和积分资源锁定。
3、TM收到执行回复,只要有一方失败则分别向其他RM发起回滚事务,回滚完毕,资源锁释放。
4、TM收到执行回复,全部成功,此时向所有RM发起提交事务,提交完毕,资源锁释放。
- 小结:
- 在准备阶段RM执行实际的业务操作,但不提交事务,资源锁定;
- 在提交阶段TM会接受RM在准备阶段的执行回复,只要有任一个RM执行失败,TM会通知所有RM执行回滚操
作,否则,TM将会通知所有RM提交该事务。提交阶段结束资源锁释放。
- XA方案的问题:
- 需要本地数据库支持XA协议。
- 资源锁需要等到两个阶段结束才释放,性能较差。
2. seata方案
Seata是由阿里中间件团队发起的开源项目 Fescar,后更名为Seata,它是一个是开源的分布式事务框架。
传统2PC的问题在Seata中得到了解决,它通过对本地关系数据库的分支事务的协调来驱动完成全局事务,是工作
在应用层的中间件。主要优点是性能较好,且不长时间占用连接资源,它以高效并且对业务0侵入的方式解决微服
务场景下面临的分布式事务问题,它目前提供AT模式(即2PC)及TCC模式的分布式事务解决方案。
2.1 设计思想
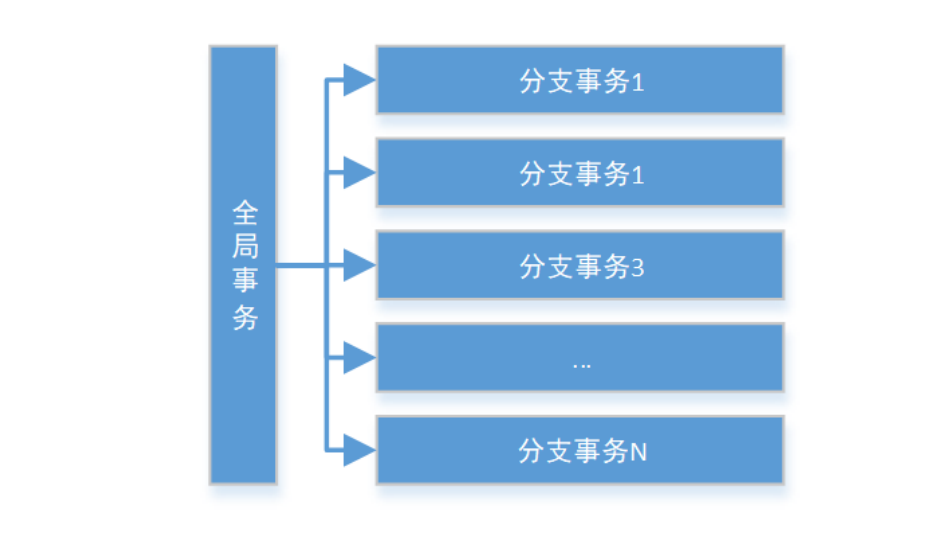
Seata把一个分布式事务理解成一个包含了若干分支事务的全局事务。全局事务的职责是协调其下管辖的分支事务
达成一致,要么一起成功提交,要么一起失败回滚。此外,通常分支事务本身就是一个关系数据库的本地事务,下
图是全局事务与分支事务的关系图:
与 传统2PC 的模型类似,Seata定义了3个组件来协议分布式事务的处理过程:
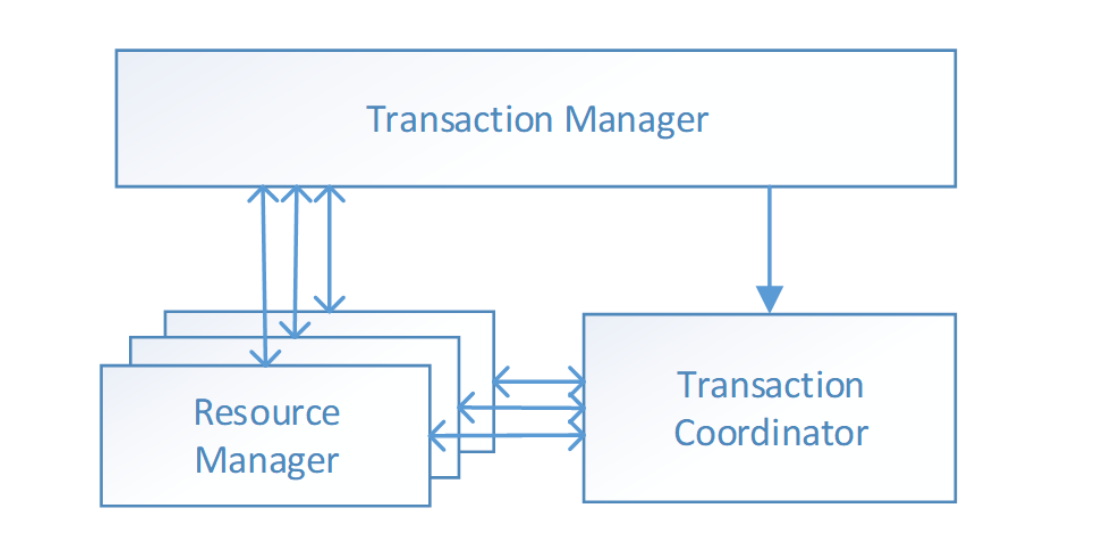
- Transaction Coordinator (TC): 事务协调器,它是独立的中间件,需要独立部署运行,它维护全局事务的运
行状态,接收TM指令发起全局事务的提交与回滚,负责与RM通信协调各各分支事务的提交或回滚。 - Transaction Manager (TM): 事务管理器,TM需要嵌入应用程序中工作,它负责开启一个全局事务,并最终
向TC发起全局提交或全局回滚的指令。 - Resource Manager (RM): 控制分支事务,负责分支注册、状态汇报,并接收事务协调器TC的指令,驱动分
支(本地)事务的提交和回滚。
2.2 工作机制
默认是at模式,以实例的模式说明.
业务表:product
id bigint(20) PRI
name varchar(100)
since varchar(100)
例如
update product set name = 'GTS' where name = 'TXC';一阶段
- 解析 SQL:得到 SQL 的类型(UPDATE),表(product),条件(where name = ‘TXC’)等相关的信息。
- 查询前镜像:根据解析得到的条件信息,生成查询语句,定位数据。
id name since
1 TXC 2014
- 执行业务 SQL:更新这条记录的 name 为 ‘GTS’。
- 查询后镜像:根据前镜像的结果,通过 主键 定位数据。
id name since
1 GTS 2014
- 插入回滚日志:把前后镜像数据以及业务 SQL 相关的信息组成一条回滚日志记录,插入到 UNDO_LOG 表中。
{
"branchId": 641789253,
"undoItems": [{
"afterImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "GTS"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"beforeImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "TXC"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"sqlType": "UPDATE"
}],
"xid": "xid:xxx"
}- 提交前,向 TC 注册分支:申请 product 表中,主键值等于 1 的记录的 全局锁 。
- 本地事务提交:业务数据的更新和前面步骤中生成的 UNDO LOG 一并提交。
- 将本地事务提交的结果上报给 TC。
二阶段-回滚
- 收到 TC 的分支回滚请求,开启一个本地事务,执行如下操作。
- 通过 XID 和 Branch ID 查找到相应的 UNDO LOG 记录。
- 数据校验:拿 UNDO LOG 中的后镜与当前数据进行比较,如果有不同,说明数据被当前全局事务之外的动作做了修 改。这种情况,需要根据配置策略来做处理,详细的说明在另外的文档中介绍。
- 根据 UNDO LOG 中的前镜像和业务 SQL 的相关信息生成并执行回滚的语句:
update product set name = 'TXC' where id = 1; - 提交本地事务。并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC。
二阶段-提交
- 收到 TC 的分支提交请求,把请求放入一个异步任务的队列中,马上返回提交成功的结果给 TC。
- 异步任务阶段的分支提交请求将异步和批量地删除相应 UNDO LOG 记录。
2.3 小结
此二阶段提交相比于lcn的二阶段提交不占用资源,整体提高效率。
3.搭建seata demo
我们搭建的微服务架构图如下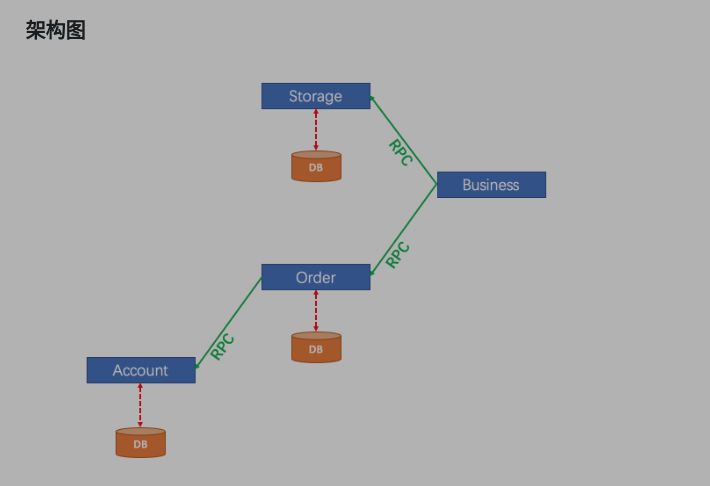
3.1 tc的下载和搭建
- 下载nacos-server-2.0.4 ,下载
- 从 github 下载seata-server软件包,将其解压缩。
- 启动nacos后,运行.
启动前要修改seata-server配置文件 修改registry { # file 、nacos 、eureka、redis、zk、consul、etcd3、sofa type = "nacos" } config { # file、nacos 、apollo、zk、consul、etcd3 type = "nacos" } ./seata-server.sh -p 8091 -h 127.0.0.1 -m file
会发现seata注册到了nacos
3.2 服务搭建
- 这里可以从官网下载实例项目. springcloud-nacos-seata,也可以下载我搭建的. 我这里只记录自己搭建的.
关于github上的配置文件,上面说:”每个应用的resource里需要配置一个registry.conf ,demo中与seata-server里的配置相同” 我自己搭建的没有配置,选择了在spring的配置文件中配置.
- 建立相关库和表
实际上,在示例用例中,这3个服务应该有3个数据库。 但是,为了简单起见,我们只创建一个数据库并配置3个数据源。
undo.log 每一个库中都要有undo.log表
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log create database seata_demo; CREATE TABLE `undo_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) NOT NULL, `context` varchar(128) NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime NOT NULL, `log_modified` datetime NOT NULL, `ext` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;为服务创建表
DROP TABLE IF EXISTS `storage_tbl`; CREATE TABLE `storage_tbl` ( `id` int(11) NOT NULL AUTO_INCREMENT, `commodity_code` varchar(255) DEFAULT NULL, `count` int(11) DEFAULT 0, PRIMARY KEY (`id`), UNIQUE KEY (`commodity_code`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; DROP TABLE IF EXISTS `order_tbl`; CREATE TABLE `order_tbl` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` varchar(255) DEFAULT NULL, `commodity_code` varchar(255) DEFAULT NULL, `count` int(11) DEFAULT 0, `money` int(11) DEFAULT 0, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; DROP TABLE IF EXISTS `account_tbl`; CREATE TABLE `account_tbl` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` varchar(255) DEFAULT NULL, `money` int(11) DEFAULT 0, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 配置文件
- pom文件
必要seata项目如下,如要连接数据库还要配置jdbc相关.<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!-- seata--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> </dependency> </dependencies> <!-- 封装的db模块 包含mybatisplus等--> <dependency> <groupId>com.rrs</groupId> <artifactId>db-spring-boot-starter</artifactId> <version>${project.version}</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> - application.yml配置
对于每个服务都要加入如下seata配置,如果要连接数据库还要配置数据源.spring: datasource: url: jdbc:mysql://127.0.0.1:3306/seata_demo?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull username: root password: root123 driver-class-name: com.mysql.cj.jdbc.Driver seata: tx-service-group: test_tx_service_group config: type: nacos nacos: serverAddr: ${spring.cloud.nacos.server-addr} group: SEATA_GROUP username: nacos password: nacos registry: type: nacos nacos: server-addr: ${spring.cloud.nacos.server-addr} group: SEATA_GROUP username: nacos password: nacos service: vgroup-mapping: vgroup: test_tx_service_group rgroup: default - bootstrap.yml
server: port: 9092 # spring: application: name: storage-service main: allow-bean-definition-overriding: true cloud: nacos: server-addr: 127.0.0.1:8848 username: nacos password: nacos
- 代码
模块图如下
common封装了必要的公共类
app作为tm,account,order,storage 作为事务参与者.
app.BusinessService
@Slf4j
@Service
public class BusinessService {
private static final String COMMODITY_CODE = "P001";
private static final int ORDER_COUNT = 1;
@Resource
private OrderFeignClient orderFeignClient;
@Resource
private StorageFeignClient storageFeignClient;
/**
* 下订单
*/
@GlobalTransactional
public void placeOrder(String userId) {
storageFeignClient.deduct(COMMODITY_CODE, ORDER_COUNT);
orderFeignClient.create(userId, COMMODITY_CODE, ORDER_COUNT);
}
}order
@Slf4j
@Service
public class OrderService {
@Resource
private AccountFeignClient accountFeignClient;
@Resource
private OrderMapper orderMapper;
//@Transactional(rollbackFor = Exception.class)
public void create(String userId, String commodityCode, Integer count) {
//订单金额
Integer orderMoney = count * 2;
Order order = new Order()
.setUserId(userId)
.setCommodityCode(commodityCode)
.setCount(count)
.setMoney(orderMoney);
orderMapper.insert(order);
accountFeignClient.reduce(userId, orderMoney);
}
}storage
@Slf4j
@Service
public class StorageService {
@Resource
private StorageMapper storageMapper;
/**
* 减库存
*
* @param commodityCode 商品编号
* @param count 数量
*/
//@Transactional(rollbackFor = Exception.class)
public void deduct(String commodityCode, int count) {
QueryWrapper<Storage> wrapper = new QueryWrapper<>();
wrapper.setEntity(new Storage().setCommodityCode(commodityCode));
Storage storage = storageMapper.selectOne(wrapper);
storage.setCount(storage.getCount() - count);
storageMapper.updateById(storage);
}
}account
@Slf4j
@Service
public class AccountService {
@Resource
private AccountMapper accountMapper;
/**
* 减账号金额
*/
//@Transactional(rollbackFor = Exception.class)
public void reduce(String userId, int money) {
if ("U002".equals(userId)) {
throw new RuntimeException("this is a mock Exception");
}
QueryWrapper<Account> wrapper = new QueryWrapper<>();
wrapper.setEntity(new Account().setUserId(userId));
Account account = accountMapper.selectOne(wrapper);
account.setMoney(account.getMoney() - money);
accountMapper.updateById(account);
}
}搭建到此时,是否可以运行了呢? 非也,当我们启动服务的时候会报错.此时需要在nacos中增加一条配置.
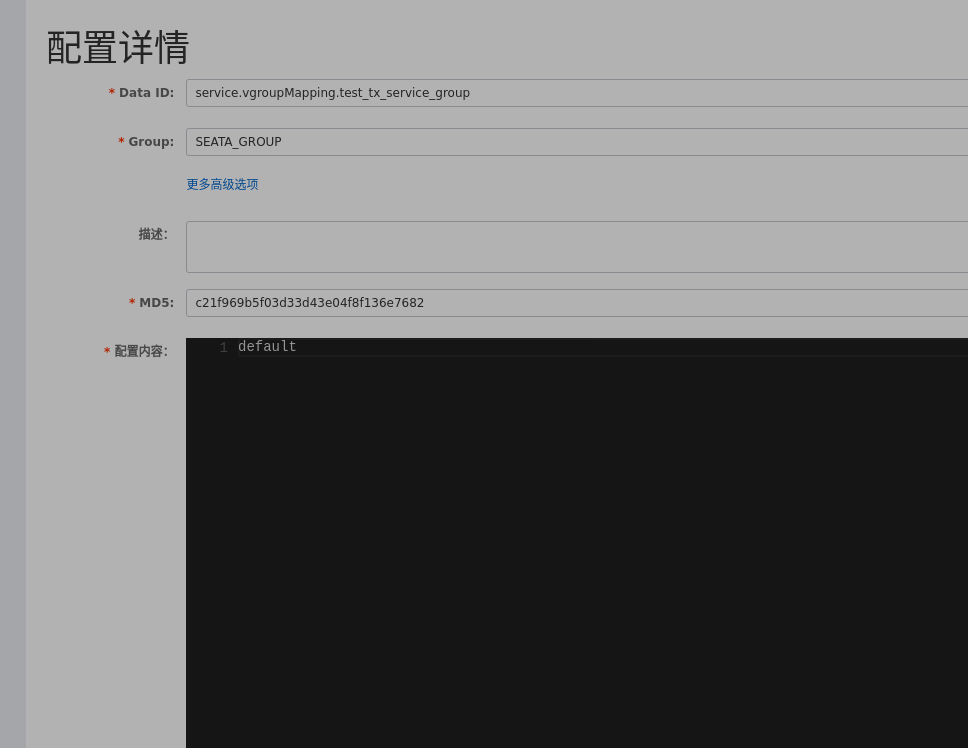
service.vgroup-mapping.test_tx_service_group=default
test_tx_service_group可以替换成自己在yml文件中配置的事务组的名称.
3.3 测试
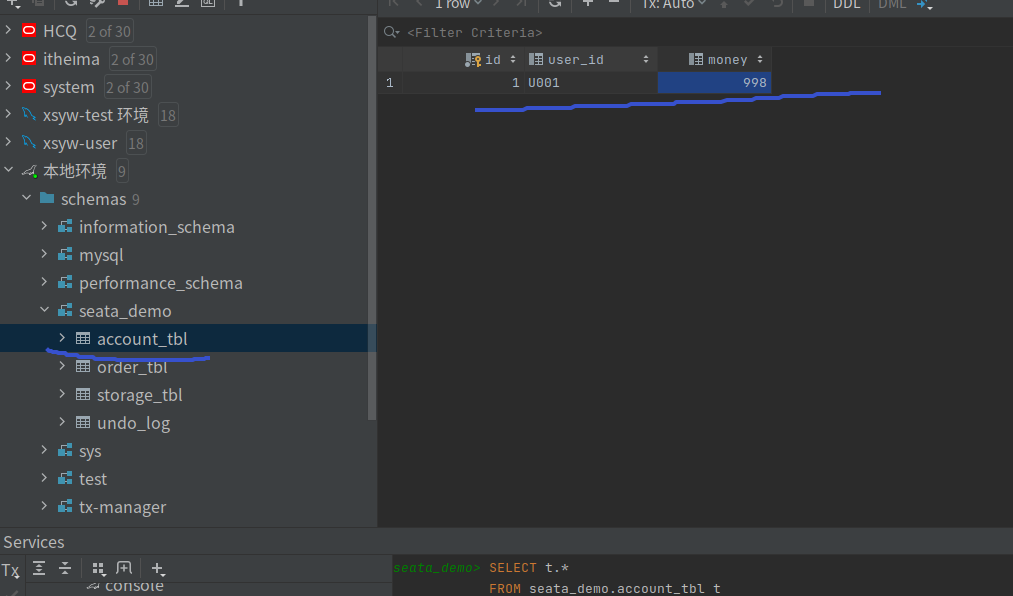
调用不抛出异常的方法,会发现正常,且数据库中数据都正常提交.
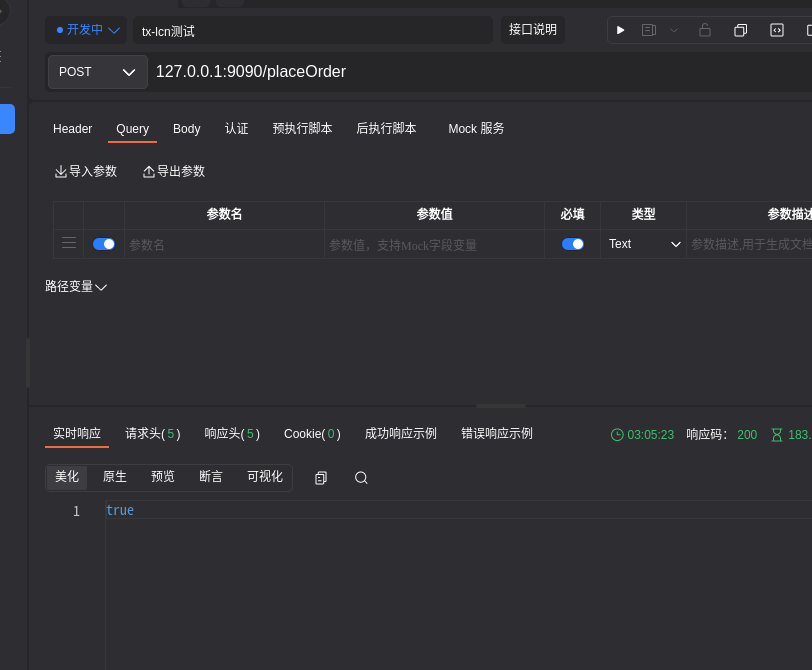
数据库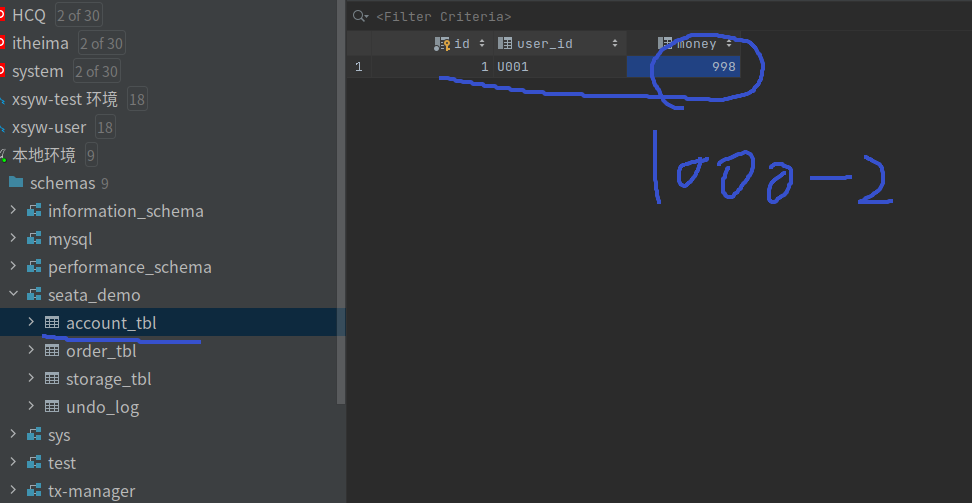
当调用抛出异常的方法,数据库中的事务都没有变化.
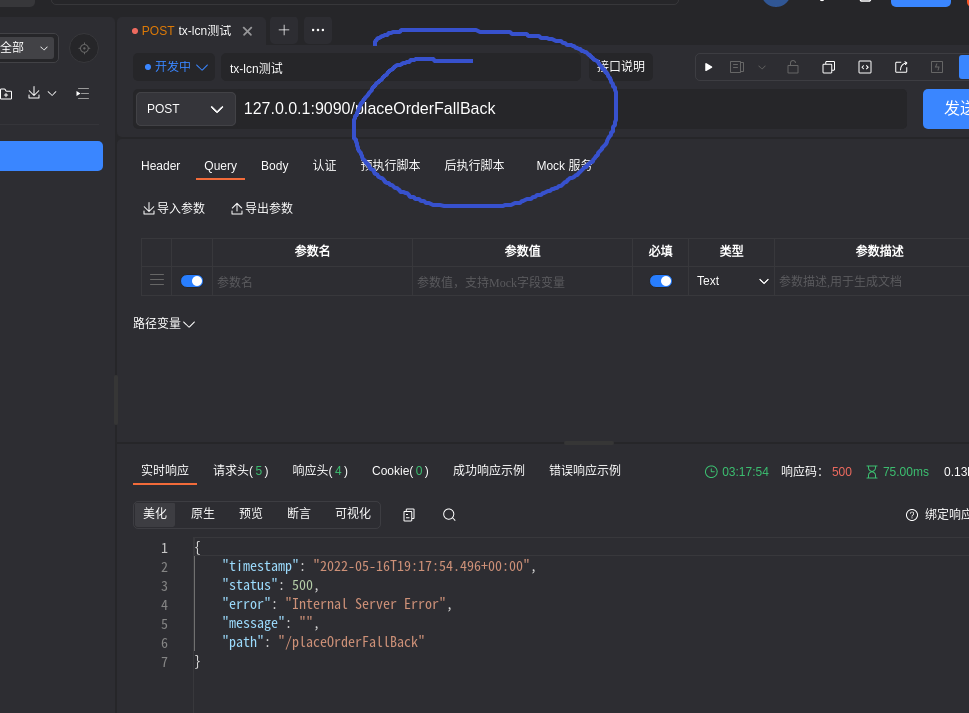
数据库
控制台输出

undo_log执行
4. 事务分组
service.vgroup-mapping.test_tx_service_group=default
还记得测试的时候,我们不加这条会出错?为什么呢?是因为seata开启了事务分组.
事务分组:seata的资源逻辑,可以按微服务的需要,在应用程序(客户端)对自行定义事务分组,每组取一个名字。
集群:seata-server服务端一个或多个节点组成的集群cluster。 应用程序(客户端)使用时需要指定事务逻辑分组与Seata服务端集群的映射关系。
4.1 事务分组如何找到后端Seata集群?
- 首先应用程序(客户端)中配置了事务分组(GlobalTransactionScanner 构造方法的txServiceGroup参数)。若应用程序是SpringBoot则通过seata.tx-service-group 配置
- 应用程序(客户端)会通过用户配置的配置中心去寻找service.vgroupMapping .[事务分组配置项],取得配置项的值就是TC集群的名称。若应用程序是SpringBoot则通过seata.service.vgroup-mapping.事务分组名=集群名称 配置
- 拿到集群名称程序通过一定的前后缀+集群名称去构造服务名,各配置中心的服务名实现不同(前提是Seata-Server已经完成服务注册,且Seata-Server向注册中心报告cluster名与应用程序(客户端)配置的集群名称一致)
- 拿到服务名去相应的注册中心去拉取相应服务名的服务列表,获得后端真实的TC服务列表(即Seata-Server集群节点列表)
我这里在yml中配置了seata.service.vgroup-mapping.事务分组名=集群名称并不管用,在nacos中配置了第三节中所说的参数才不报错. 难道是因为开启了nacos才从nacos中取这个配置项?
4.2 为什么要事务分组
这里多了一层获取事务分组到映射集群的配置。这样设计后,事务分组可以作为资源的逻辑隔离单位,出现某集群故障时可以快速failover,只切换对应分组,可以把故障缩减到服务级别,但前提也是你有足够server集群。
client-查找到server的过程呢刚
- 读取配置 通过NacosConfiguration远程读取seata配置参数
- 获取事务分组(服务启动时加载配置) spring/springboot可配置在yml、properties中,对应值”my_test_tx_group”即为事务分组名,若不配置则默认以:spring.application.name值+”-seata-service-group”拼接后的字符串作为分组名
- 查找TC集群名 拿到事务分组名”my_test_tx_group”拼接成”service.vgroupMapping.my_test_tx_group”从配置中心查找到TC集群名clusterName为”default”
- 查找TC服务 根据serverAddr和namespace以及clusterName在注册中心找到真实TC服务列表
小结
- seata的配置方式多种多样,且因为阿里一直在维护,配置也都是一直在更新. 阿里的github上有多种架构下的配置和demo.
- 如果我们要使用seata,那么在项目的架构搭建好时就要配置好seata,且不要轻易的改动.
- 上面我们探究了seata的原理,搭建了demo,seata的at模式本质上是一种事务失败后进行全局事务的手动回滚,每个分支事务会读取undo_log,进行数据的回滚.
- 阿里有很多组件,但是也有好多组件不能做到开箱即用,最早接触的fastdfs就这样,canal也是,seata我搭建起来也感觉不太好,但是这个组件也经过了阿里的广泛应用,所以必要时项目中要用还是要认真的学习一下的.

