日志处理之ELK
之前的项目中日志,开发环境下暂时还是在linux服务器上查看文件,但由于也是采用了微服务的方式,即使是一个服务背后也是一个集群的机器在运行,如果逐台机器去查看日志显然是很费力的,也不现实。我想项目上线之后可能会重新处理一下日志.依然要放到es中,所以这部分也要有所准备.
elk是什么
ELK其实是Elasticsearch,Logstash 和 Kibana三个产品的首字母缩写,这三款都是开源产品。
用这三个组件可以搭建日志系统.
1. 搭建es
实体机
首先,到官网下载安装包,然后使用tar -zxvf命令解压。
如果本身没有用root账户,也不用修改配置文件的.
./bin/elasticsearch -d
如果用了root账户,需要修改配置文件
#cluster.name: es-application
#node.name: node-1
#对所有IP开放
network.host: 0.0.0.0
#HTTP端口号
http.port: 9200
#elasticsearch数据文件存放目录
path.data: /path/elasticsearch-7.15.2/data
#elasticsearch日志文件存放目录
path.logs: /path/elasticsearch-7.15.2/logs
# path 修改成es所在目录还需要创建一个账户用于启动es
# 创建用户
useradd es
# 设置密码
passwd es
# 赋予用户权限
chown -R es:es /path/elasticsearch-7.15.2/
# 切换用户
su yehongzhi
# 启动 -d表示后台启动
./bin/elasticsearch -d访问9200端口 看到如下即为成功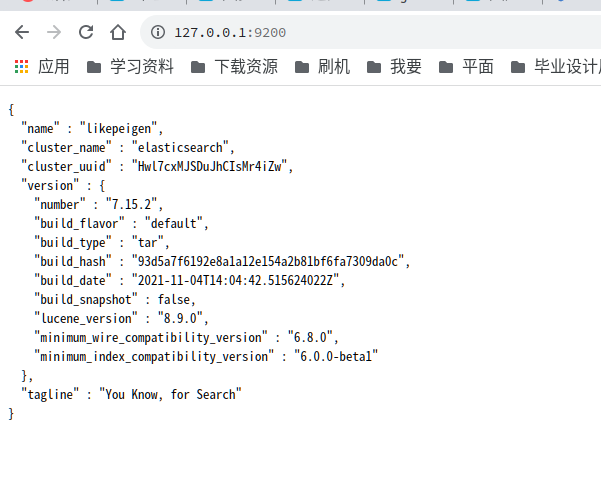
上述没有密码
若要为es加入密码
配置文件加入
xpack.security.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true启动es后执行
elasticsearch-setup-passwords interactive 按照提示为几个用户设置密码,分别为es,logstash,beats,kibana.
2. 搭建Kibana
解压
修改配置文件
server.port: 5601
server.host: "localhost"
elasticsearch.hosts: ["http://localhost:9200"]
# 这两项如es设置了密码配置
elasticsearch.username: "kibana_system"
elasticsearch.password: "elas123"
i18n.locale: "zh_CN"增加用户
# 创建用户
useradd kibana
# 设置密码
passwd kibana
# 赋予用户权限
chown -R kibana:kibana /path/kibana/
#切换用户
su kibana
#非后台启动,关闭shell窗口即退出
./bin/kibana
#后台启动
nohup ./bin/kibana &
#实际上如果本身就不是root用户上面两步都不用做,直接
nohup ./bin/kibana & 启动后在浏览器打开http://localhost:5601,可以看到kibana的web交互界面:
3. 搭建logstash
自定义配置文件
logstash-sample.conf
input {
file{
path => ['/usr/local/user/*.log']
type => 'user_log'
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "user-%{+YYYY.MM.dd}"
}
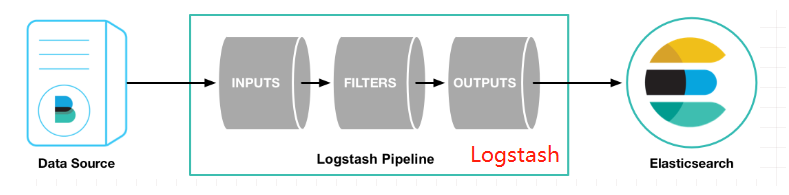
}input表示输入源,output表示输出,还可以配置filter过滤,架构如下:
配置好之后就能在es中查看.
上述配置文件是通过文件输入,有时我们希望通过网络直接传输到logstash
配置文件可以如下.
input {
tcp {
mode => "server"
#这个需要配置成本机IP,不然logstash无法启动
host => "127.0.0.1"
#端口号
port => 4567
codec => json_lines
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
action=>"index"
#ES索引名称(自己定义的)
#index => "%{[appname]}-%{+YYYY.MM.dd}"
index => "log"
user => "elastic"
password => "elas123"
}
stdout{
codec => json_lines
}
}同时服务中也要加入依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
</dependency>
logback.xml文件
增加如下文件
<!--发布到logstash的日志-->
<appender name="stash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!-- 这是是logstash服务器地址 端口-->
<destination>127.0.0.1:4567</destination>
<!--输出的格式,推荐使用这个-->
<!-- 日志输出编码 -->
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"msg": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>对应的java服务
Slf4j
@RestController
public class DemoController {
@Autowired
private ApplicationContext applicationContext;
@Resource
RedisDistributedLockFactory factory;
@GetMapping("/demo")
public String getBeanInfo(){
log.info("测试干阿嘎嘎嘎嘎"+System.currentTimeMillis());
log.info("测试干阿嘎嘎嘎嘎"+System.currentTimeMillis());
log.info("测试干阿嘎嘎嘎嘎"+System.currentTimeMillis());
log.info("测试干阿嘎嘎嘎嘎"+System.currentTimeMillis());
log.info("测试干阿嘎嘎嘎嘎"+System.currentTimeMillis());
//bean 的名字由方法名确定
BeanList beanList = (BeanList)applicationContext.getBean("getBeanList");
for (Mybean mybean : beanList.getList()) {
System.out.println(mybean.toString());
}
return "";
}
}
调用文件 会发现es中有数据了.es会自动的根据传入的文档创建索引.
4. 还有一个组件filebeat
如果Logstash需要添加插件,那就全部服务器的Logstash都要添加插件,扩展性差。所以就有了FileBeat,占用资源少,只负责采集日志,不做其他的事情,这样就轻量级,把Logstash抽出来,做一些滤处理之类的工作。
修改filebeat.yml
#输入源
filebeat.inputs:
- type: log
enabled: true
paths:
- /path/*.log
#输出,Logstash的服务器地址
output.logstash:
hosts: ["localhost:5044"]
#输出,如果直接输出到ElasticSearch则填写这个
#output.elasticsearch:
#hosts: ["localhost:9200"]
#protocol: "https"
Logstash的配置文件logstash-sample.conf
#输入源改成beats
input {
beats {
port => 5044
codec => "json"
}
}
然后启动FileBeat:
#后台启动命令
nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &再启动Logstash:
#后台启动命令
nohup ./bin/logstash -f /usr/logstash-7.15.2/config/logstash-sample.conf &判断启动成功呢,看Logstash应用的/logs目录下的logstash-plain.log日志文件.
小结:
es和Logstash,Kibana可做日志收集,但也不仅仅这样.
- 可以采用logback直接发送到Logstash.
- 也可以吧日志都发送到redis,然后在在Logstash采集,到es.
- 也可以卡夫卡生产日志,直接消费到es.
- 卡夫卡消费到Logstash,然后到es.
总之不同场景下有不同考量,一种方式达到了瓶颈可以采用另一种.

